Originally a guest post on June 25, 2012 at Climate Etc
Re: Data inconsistencies in Forest, Stone and Sokolov (2006) GRL paper 2005GL023977 ‘Estimated PDFs of climate system properties including natural and anthropogenic forcings‘
In recent years one of the most important methods of estimating probability distributions for key properties of the climate system has been comparison of observations with multiple model simulations, run at varying settings for climate parameters. Usually such studies are formulated in Bayesian terms and involve ‘optimal fingerprints’. In particular, equilibrium climate sensitivity (S), effective vertical deep ocean diffusivity (Kv) and total aerosol forcing (Faer) have been estimated in this way. Although such methods estimate climate system properties indirectly, the models concerned, unlike AOGCMs, have adjustable parameters controlling those properties that, at least in principle, are calibrated in terms of those properties and which enable the entire parameter space to be explored.
In the IPCC’s Fourth Assessment Report (AR4), an appendix to WGI Chapter 9, ‘Understanding and attributing climate change’, was devoted to these methods, which provided six of the chapter’s eight estimated probability density functions (PDFs) for S inferred from observed changes in climate. Estimates of climate properties derived from those studies have been widely cited and used as an input to other climate science work. The PDFs for S were set out in Figure 9.20 of AR4 WG1, reproduced below.
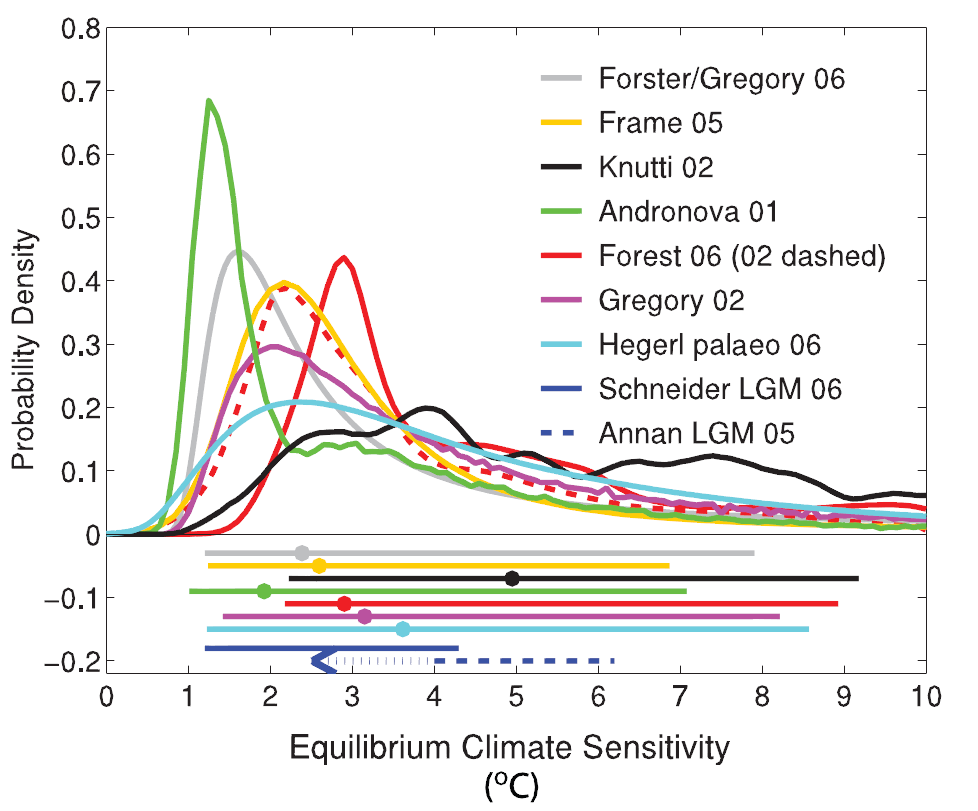
The results of Forest 2006 and its predecessor study Forest 2002 are particularly important since, unlike all other studies utilising model simulations, they were based on direct comparisons thereof with a wide range of instrumental data observations – surface, upper air and deep-ocean temperature changes – and they provided simultaneous estimates for Kv and Faer as well as S. Jointly estimating Kv and Faer together with S is important, as it avoids dependence on existing very uncertain estimates of those parameters. Reflecting their importance, the IPCC featured both Forest studies in Figure 9.20. The Forest 2006 PDF has a strong peak which is in line with the IPCC’s central estimate of S = 3, but the PDF is poorly constrained at high S.
I have been trying for over a year, without success, to obtain from Dr Forest the data used in Forest 2006. However, I have been able to obtain without any difficulty the data used in two related studies that were stated to be based on the Forest 2006 data. It appears that Dr Forest only provided pre-processed data for use in those studies, which is understandable as the raw model dataset is very large.
Unfortunately, Dr Forest reports that the raw model data is now lost. Worse, the sets of pre-processed model data that he provided for use in the two related studies, while both apparently deriving from the same set of model simulation runs, were very different. One dataset appears to correspond to what was actually used in Forest 2006, although I have only been able to approximate the Forest 2006 results using it. In the absence of computer code and related ancillary data, replication of the Forest 2006 results is problematical. However, that dataset is compatible, when using the surface, upper air and deep-ocean data in combination, with a central estimate for climate sensitivity close to S = 3, in line with the Forest 2006 results.
The other set of data, however, supports a central estimate of S = 1, with a well constrained PDF.
I have written the below letter to the editor-in-chief of the journal in which Forest 2006 was published, seeking his assistance in resolving this mystery. Until and unless Dr Forest demonstrates that the model data used in Forest 2006 was correctly processed from the raw model simulation run data, I cannot see that much confidence can be placed in the validity of the Forest 2006 results. The difficulty is that, with the raw model data lost, there is no simple way of proving which version of the processed model data, if either, is correct. However, so far as I can see, the evidence points to the CSF 2005 version of the key surface temperature model data, at least, being the correct one. If I am right, then correct processing of the data used in Forest 2006 would lead to the conclusion that equilibrium climate sensitivity (to a doubling of CO2 in the atmosphere) is close to 1°C, not 3°C, implying that likely future warming has been grossly overestimated by the IPCC.
This sad state of affairs would not have arisen if Dr Forest had been required to place all the data and computer code used for the study in a public archive at the time of publication. Imposition by journals of such a requirement, and its enforcement, is in my view an important step in restoring trust in climate science amongst people who base their beliefs on empirical, verifiable, evidence.
************
Dr E Calais
Editor-in-Chief, Geophysical Research Letters,American Geophysical Union
June 23, 2012
Re: Data inconsistencies in Forest, Stone and Sokolov (2006) GRL paper 2005GL023977 ‘Estimated PDFs of climate system properties including natural and anthropogenic forcings’
Dear Dr Calais:
I contacted you last summer about the failure by Dr Chris Forest to provide requested data and computer code used in Forest 2006, an observationally constrained study of key climate parameters. My primary interest in Forest 2006 is the statistical inference methods used, which I consider to be flawed. I have still not received any data or code from Dr Forest, despite repeated promises to make data available. However, the issues I raise in this letter are more serious than simple failure to provide materials; they concern apparent alteration of data.
In summary, I have copies of datasets used in two studies related to Forest 2006, both of which should contain the same temperature data as used in Forest 2006 (save for the deep-ocean observational data). Only one of the datasets is consistent with Forest 2006. The other dataset was used in a 2005 study (CSF 2005 – detailed in paragraph 1 below), certain results of which relating to the key surface temperature ‘diagnostic’ were relied upon in Forest 2006 to support a critical parameter choice. Dr Forest has stated that the surface diagnostic data used in Forest 2006 was identical to that used in CSF 2005. However, the CSF 2005 surface diagnostic model data that I have cannot be the same as the data used in Forest 2006 and, moreover, it points to a much lower estimate of climate sensitivity than that given in the Forest 2006 results.
I would ask you to investigate thoroughly my concerns. If Dr Forest is unable to demonstrate, using data, code and other information that is made publicly available, that the changes between the CSF 2005 and the Forest 2006 model data were made to correct processing errors, and did accurately do so, then I would ask you to consider whether Forest 2006 should be withdrawn by GRL.
In addition, I ask you to require Dr Forest to provide copies of the following data and computer code to me without further delay:
- all the processed MIT model, observational and AOGCM control-run data used in Forest 2006 for the computation of the likelihood function from each diagnostic;
- all code and ancillary data used to generate that data from the raw data used
- all code and ancillary data used to generate the likelihood functions from the processed data
I set out details of my concerns, and the evidence supporting them, in the numbered paragraphs below.
1. I have obtained two sets of processed data, matching in form that used in Forest et al. 2006, which Dr Forest provided to his co-authors for use in two related studies: Curry C, Sansó B and Forest C, Inference for climate system properties, 2005, AMS Tech. Rep. ams2005-13, Am. Stat. Assoc. (CSF 2005), cited in Forest 2006; and Sansó B, Forest C and Zantedeschi D, Inferring Climate System Properties Using a Computer Model, Bayes. Anal., 2008, 3,1–62 (SFZ 2008). The values of the data that Dr Forest provided for these two studies differ substantially, and lead to completely different central estimates of climate sensitivity: 1 K and 3 K respectively.
2. Forest et al. 2006 compares observations of multiple surface, upper air and deep-ocean temperature changes with simulations thereof by the MIT 2D climate model run at many climate parameter settings. Internal climate covariability affecting the variables in each of these three ‘diagnostics’ is estimated using AOGCM long-control-run data. The surface diagnostic (mean temperatures for four latitude bands averaged over each of the five decades 1946–55 to 1986–95) is most informative as to how likely each climate parameter combination is. The raw MIT model, observational and AOGCM control run data was processed to match the specifications of the three diagnostics before the statistical inference methods were applied. Dr Forest states that the raw MIT model data has been lost, making it impossible to replicate fully, and so verify, the study.
3. A preprint version of Forest 2006 was published in September 2005 as MIT Joint Program Report No. 126. Apart from in a small number of places, in particular where references were made to use of an older deep-ocean observational dataset (Levitus et al 2000 rather than 2005), the MIT report version was almost identically worded to the final version. By mistake, in Figures S1a and S1b of the GRL Auxiliary Material, Dr Forest included the graphs from the MIT Report version, showing very different probability densities (PDFs) for climate sensitivity than those in Figure 2 of the main text of Forest 2006 in GRL. I was surprised that simply changing the ocean dataset had such a major impact on the shape of these PDFs, but this may reflect problems with the surface diagnostic dataset used, as discussed below.
4. Bruno Sansó has provided me with a copy of the tar file archive, dated 23 May 2006, of processed data for the surface and upper air diagnostics, which Dr Forest sent him for use in SFZ 2008. The latter paper states that the data it used is the same as that in Forest 2006. Bruno Sansó also sent me, separately, a copy of the deep-ocean diagnostic model, observational and control data used in SFZ 2008. I am inclined to believe that the SFZ 2008 surface and upper air diagnostic data was that used in Forest 2006. Its surface model data matches Forest 2006 Figure 1(a). Using the SFZ 2008 tar file archive data in combination with the deep-ocean diagnostic model and control-run data used in SFZ 2008, and a deep-ocean diagnostic observational trend calculated from the Levitus et al 2005 dataset, I can produce broadly similar climate parameter PDFs to those in the Forest 2006 main results (Figure 2: GSOLSV, κsfc = 16, uniform prior), with a peak climate sensitivity around S = 3. However, doing so necessitates what I regard as an overoptimistic assumption as to uncertainty in the deep-ocean diagnostic observational trend, and I have been unable even approximately to match the GSOLSV, κsfc = 14 climate sensitivity PDF in Figure 2 of Forest 2006. The lack of a better match could conceivably relate to different treatment resulting from undisclosed methodological choices or ancillary data used by Dr Forest. Alternatively, the deep-ocean model data that was used in Forest 2006 may differ from that used in SFZ 2008, which matches the deep-ocean data used in the CSF 2005 study, provided at an earlier date than was the SFZ 2008 surface and upper air data.
5. Charles Curry has made available the data that, a few months before submitting Forest 2006 to GRL, Dr Forest provided for use in CSF 2005. I can reproduce exactly the numbers in Figure 1 of CSF 2005 using this data. The CSF 2005 surface and upper air diagnostic observational data is almost identical to that provided for SFZ 2008, but the CSF 2005 model data is quite different, as is the control data. It is impossible for the CSF 2005 data to have produced the results in Forest 2006, for two reasons:
a) the CSF 2005 surface control data covariance matrix is virtually singular, indicating that the raw data from the (GFDL) AOGCM control run had been misprocessed. Its use leads to extremely poorly constrained, pretty well information-less, climate sensitivity PDFs;
b) when used with the HadCM2-derived surface control data covariance matrix from the SFZ 2008 data, which I have largely been able to agree to raw data from the HadCM2 AOGCM control run (which data Dr Forest has confirmed was used for the Forest 2006 main results), the CSF 2005 surface model and observational data produces, irrespective of which upper air and deep-ocean dataset is used, a strongly peaked PDF for climate sensitivity, centred close to S = 1, not S = 3 as per Forest 2006.
Moreover, the relevant CSF 2005 model data is inconsistent with the surface model data graph in Forest 2006 Figure 1(a).
6. CSF 2005 concentrated on the problem of selecting the number of eigenvectors to retain when estimating inverse covariance matrices from the AOGCM control run data. The study was cited in Forest 2006 as supporting, based on the Forest 2006 data, the selection of the number of eigenvectors retained (κsfc = 16) when estimating the AOGCM control data covariance matrix for the surface diagnostic. Forest 2006 makes clear that its results are highly sensitive to this choice, stating: ‘the method for truncating the number of retained eigenvectors (i.e., patterns of unforced variability) is critical’ and ‘In a separate work on Bayesian selection criteria, Curry et al. [2005] using our data find that a break occurs at κsfc = 16 and thus we select this as an appropriate cut-off’.
7. It is clearly implied, and necessarily so, that CSF 2005 used the same surface model, observational and control data as Forest 2006. And indeed Dr Forest has recently confirmed that the surface model and control-run temperature data used in Forest 2006 was the same as that used in CSF 2005. I enquired of Dr Forest as follows:
However, I note that the GRL paper contains the same statement as the MIT Report preprint about the Curry, Sansó and Forest 2005 work finding, using your data, that a break occurs at k_sfc = 16 and thus you selected that as an appropriate cut-off. It would not seem correct for that statement to be have been made in the GRL version if you had changed significantly the processed data used in the surface diagnostic after the work carried out by Curry, even assuming there was a valid reason for altering the data.
Dr Forest replied:
The Curry et al. paper examined the posteriors separately for the surface temperature data, the ocean data, and the upper air data and never estimated a posterior using all three diagnostics. So the results from the Curry et al study is valid for the surface data diagnostics as given in the Forest et al. (2006, GRL) study.
8. In response to this I enquired further:
But I think you are saying in your email that the version of the analyzed model data that was used in the Curry, Sansó and Forest 2005 paper was the same as that used in both the pre-print MIT Report 126 and the final GRL 2006 versions of the above study, at least for the key surface diagnostic that I was asking about – otherwise the results of the Curry 2005 paper would not be directly applicable to the surface diagnostic used in the GRL 2006 study. Have I understood you correctly?
Dr Forest replied:
Yes, the Curry et al. 2005 paper used the same surface data in their results and therefore, it is directly applicable to the 2006 study.
9. Dr Forest’s statement that the surface diagnostic data used in CSF 2005 was the same as in Forest 2006 is demonstrably incorrect, for the reasons given in paragraph 5. Comparing the CSF 2005 data with the SFZ 2008 data – which data does appear consistent with that used in Forest 2006 – the two sets of observational data are nearly identical, but both the model and the control run data are very different. It seems clear that the problem with the processing of the CSF 2005 surface control data was discovered and rectified, since neither the GFDL nor the HadCM2 surface control data matrices in the SFZ 2008 data are near singular. Moreover, analysis of the model data, discussed below, suggests that, assuming one dataset has been processed correctly, it is the CSF 2005 rather than the SFZ 2008 data that is valid.
10. Although, having available only the decadally averaged data for four latitude bands used in the surface diagnostic, I have been unable to identify an exact relationship between the datasets, the SFZ 2008 surface data is evidently derived from the same 499 MIT model runs as is the Curry data. Regressing model noise patterns extracted from the SFZ 2008 surface model data on those from the CSF 2005 data produces high r2 statistics. Furthermore, the regression coefficients on the data for the same and earlier decades suggest that the SFZ 2008 surface data is delayed by several years relative to CSF 2005 data. Since, per Forest 2006, the MIT model runs only extend to 1995, model data incorporating a delay could not have matched the timing of the observational surface diagnostic data.
11. The finding of an apparent delay in the SFZ 2008 data corresponds with that data showing, as it does, a lower temperature rise in each of the later decades than does the CSF 2005 data, for any given climate sensitivity. Accordingly, the SFZ 2008 data requires a much higher climate sensitivity to match the rise in observed temperatures. Indeed, for over three-quarters of the ocean diffusivity range, the SFZ 2008 model data matches the five decades of observational data as well at the maximum climate sensitivity of S = 10 used in Forest 2006 as it does at S = 3, which is very odd. That finding, supported by Forest 2006 Fig.S.7, means that the SFZ 2008 surface model data on their own provide very little discrimination against high climate sensitivity, unlike the CSF 2005 data. The graph appended to this letter illustrates this point. The CSF 2005 model data produce an extremely well constrained sensitivity PDF, centred around S = 1, while the SFZ 2008 model data produce a PDF that is completely unconstrained at high S. It appears that the other diagnostics, particularly the deep-ocean diagnostic, constrained the final Forest 2006 PDF for S, disguising the failure of the surface diagnostic to do so.
12. The (less influential) upper air model data used in SFZ 2008 also differs from the corresponding CSF 2005 data, although evidently being derived from the same model runs. The pattern of changes between the CSF 2005 and SFZ 2008 upper air model data is complex and varies by pressure level and latitude. The changes appear to make the upper side of the final PDF for S worse constrained.
13. I made Dr Forest aware over a week ago that I had the CSF 2005 and SFZ 2008 processed datasets, and invited him to provide within seven days a satisfactory explanation of the changes made to the data, and evidence that adequately substantiates his apparently incorrect statements. I implied that such evidence would consist of copies of all the processed data used in Forest 2006 for the computation of the error r2 statistic produced by each diagnostic; a copy of all computer code used for subsequent computation and interpolation; and the code used to generate both the CSF 2005 and the Forest 2006 processed MIT model, observational and AOGCM control-run data from the raw data, including all ancillary data used.
I have received no response from Dr Forest.
I look forward to hearing from you as to the action that you are taking in this matter, and its outcome.
Yours sincerely
Nicholas Lewis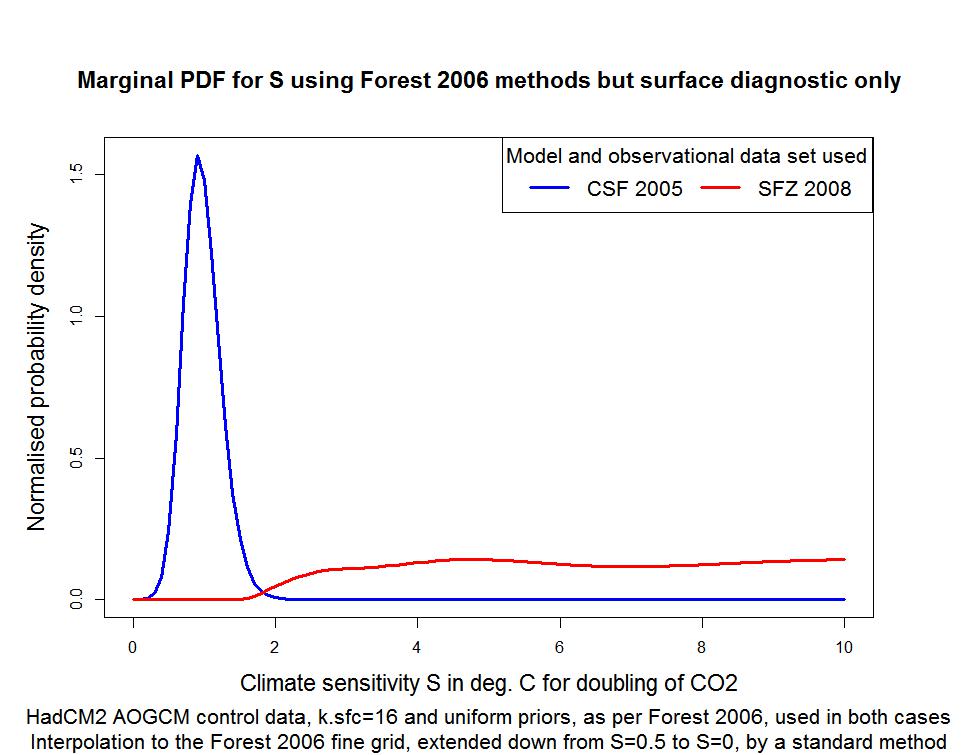
Biosketch. Nic Lewis’ academic background is mathematics, with a minor in physics, at Cambridge University (UK). His career has been outside academia. Two or three years ago, he returned to his original scientific and mathematical interests and, being interested in the controversy surrounding AGW, started to learn about climate science. He is co-author of the paper that rebutted Steig et al. Antarctic temperature reconstruction (Ryan O’Donnell, Nicholas Lewis, Steve McIntyre and Jeff Condon, 2011, Improved methods for PCA-based reconstructions: case study using the Steig et al. (2009) Antarctic temperature reconstruction, Journal of Climate – print version at J.Climate or preprint here).
Nic’s previous guest posts at Climate Etc:
- The IPCC’s alteration of Forster & Gregory’s model independent climate sensitivity results
- Climate sensitivity follow up
Note: Nic’s open letter to the IPCC led to the IPCC issuing an Erratum regarding what prior distribution had been used for the Gregory 2002 climate sensitivity PDF in Figure 9.20 of AR4 WG1.
JC comment: I have been discussing this issue with Nic over the past two weeks. Particularly based upon his past track record of careful investigation, I take seriously any such issue that Nic raises. Forest et al. (2006) has been an important paper, cited over 100 times and included in the IPCC AR4. Observationally constrained studies along the lines of Forest et al. 2006, correctly designed and carried out, may be able to provide much tighter estimates of climate sensitivity than has previously looked possible, particularly with another 16 years temperature data now available since that used by Forest et al. 2006. Given the importance of the topic of sensitivity, we need to make sure that the paper has done what it says it has done, is sound methodologically, and that it has been interpreted correctly by the IPCC.
This particular situation raises some thorny issues, that are of particular interest especially in light of the recent report on Open Science from the Royal Society:
i) ideally someone would audit Nic’s audit, perhaps Nic can make the relevant information that he has available. How should the editor deal with this situation?
ii) what should the authors be responsible for providing in terms of the documentation? Obviously the observed and model data, but what about the code? Or is sufficient documentation in the supplementary information adequate?
iii) assuming for the sake of argument that there is a serious error in the paper: should a paper be withdrawn from a journal, after it has already been heavily cited?
iv) GRL has a policy that it does not accept comments on published papers; rather, if an author has something substantive to say they should submit a stand alone paper. Personally, I think the Comment function is preferable to withdrawing a paper that has already been heavily cited, with the Comment linked electronically to the original article.
v) what should the ‘statute of limitations’ be for authors in terms of keeping all of the documentation, model versions, etc. for possible future auditing? While digital media makes this relatively easy, I note that when I moved from Colorado to Georgia, I got rid of all of the carefully accumulated documentation for the papers written in the first two decades of my career (9 track tapes, books of green and white computer paper print out, etc.), although the main datasets were publicly archived in various places. But this is obviously suboptimal. Who is responsible for archiving this information? Some of these issues are discussed in the Royal Society Report.
vi) other issues that you can think of?
Leave A Comment